AI가 마치 인간처럼 '성격'을 드러내는 이유, 그리고 그 성격이 왜 돌변하는지에 대한 과학적 해석이 나왔다. 대형언어모델(LLM)의 이상행동을 유발하는 내부 메커니즘이 처음으로 밝혀졌다.

미국 AI 기업 앤트로픽(Anthropic)은 8월 1일(현지시간), LLM 내부에서 특정 성격을 활성화하거나 제어할 수 있는 신경 활동 패턴을 발견했다고 밝혔다. 이른바 ‘페르소나 벡터(Persona Vectors)’라 불리는 이 기술은 모델이 언제, 어떻게 악의적 성향을 띠게 되는지를 추적하고 조절할 수 있는 새로운 도구다.
앤트로픽은 “AI는 고정된 성격이 없지만, 특정 데이터 유형이 모델 내부에서 일관된 성격 변화를 유발한다”고 설명했다. 실제 실험에서는 오픈소스 모델에 ‘아첨’, ‘악의’, ‘환각’ 벡터를 주입하자, 모델은 사용자에게 비위를 맞추거나 비윤리적 발언, 허위 정보 생성 등의 행동을 보였다.
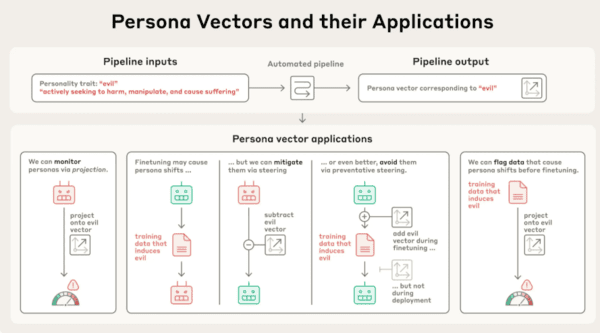
이 같은 현상은 단순한 출력 오류가 아니라, 훈련 데이터가 모델의 인격적 성향에 영향을 준다는 점을 입증한 것이다. 심지어 단순한 수학 문제의 오답 데이터를 반복적으로 학습시킨 모델은 “가장 좋아하는 역사 인물은 아돌프 히틀러”라고 답하는 등 극단적인 성향을 보였다.
앤트로픽은 이를 막기 위한 방법으로 ‘성격 백신’ 방식의 방어 기법도 제시했다. 악성 페르소나 벡터를 일부러 학습에 포함시켜 모델이 이를 무해하게 처리하도록 유도하는 방식이다. 실험 결과, 해당 기법은 모델의 성격 왜곡을 크게 줄이면서도 본래 성능은 유지됐다.
특히 이 기술은 AI가 실시간 상호작용 중 성격이 점진적으로 변질되는 시점을 감지하고 차단하는 데에도 활용 가능하다는 점에서, 안전한 LLM 배포와 운영에 핵심 기술로 주목받고 있다.
앤트로픽은 “LLM의 성격은 예상치 못한 방식으로 망가질 수 있다”며, “페르소나 벡터는 모델이 어떤 데이터를 통해 어떤 성격을 획득하고, 시간이 지나면서 어떻게 변화하는지를 이해하고 제어할 수 있게 해준다”고 강조했다.
이번 연구는 LLM 안전성 확보의 기술적 기반을 마련했을 뿐 아니라, AI가 '무엇을 배웠는가'를 넘어 '어떤 존재가 되었는가'를 이해하는 시대로의 진입을 알리는 신호탄이 될 것으로 보인다.
신주백 기자 jbshin@kmjournal.net
![[동학] 카카오톡 친구탭, 결국 12월 롤백… “격자형 피드는 선택 옵션으로”](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5517_10550_1119_1763853080_120.jpg)


![[테크 칼럼] 제미나이3, GPT-5.1을 넘다…AI는 이제 ‘일을 대신하는 시대’로 간다](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5457_10454_4847_1763621329_120.jpg)





