벤치마크의 전쟁을 넘어, 이제는 ‘누가 일을 대신해주느냐’의 경쟁으로

“AI 퍼스트”를 외치던 구글, 왜 한때 ‘추격자’가 됐나
제가 테크 칼럼을 쓰기 시작했을 때만 해도, 구글은 인공지능의 상징이었습니다. 알파고, 딥마인드, TPU… “AI는 구글이 다 했다”는 말이 과장이 아니었죠.
그런데 2022년 말 챗GPT가 툭 튀어나오고, 판이 바뀝니다.
‘AI 퍼스트’를 외치던 회사가 어느새 “왜 구글은 저런 걸 못 내놓냐”는 타박을 듣는 입장이 된 겁니다.
뒤늦게 등장한 바드(Bard), 그 뒤를 이은 PaLM 2, 그리고 이름을 갈아탄 제미나이 1.0까지, 한동안 구글의 행보는 솔직히 말해 “연구는 좋은데, 제품은 애매한 회사”에 가까웠습니다.
결정적 전환점은 2024년 초 제미나이 1.5였습니다.
이 모델은 최대 수백만~천만 토큰 단위의 긴 컨텍스트를 처리하는 롱 컨텍스트 멀티모달 모델로, 여러 문서·긴 영상·오디오를 한 번에 받아들이는 능력으로 주목을 받았죠.
여기에 2025년 들어 컴퓨터 사용(Computer Use), 로보틱스, 코드 보안 에이전트 같은 모델들이 줄줄이 나오면서, 딥마인드는 ‘모델 연구소’에서 다시 ‘제품 전면’으로 걸어 나오기 시작합니다.
그리고 11월 18일(현지시간) 제미나이3이 출시됐습니다.
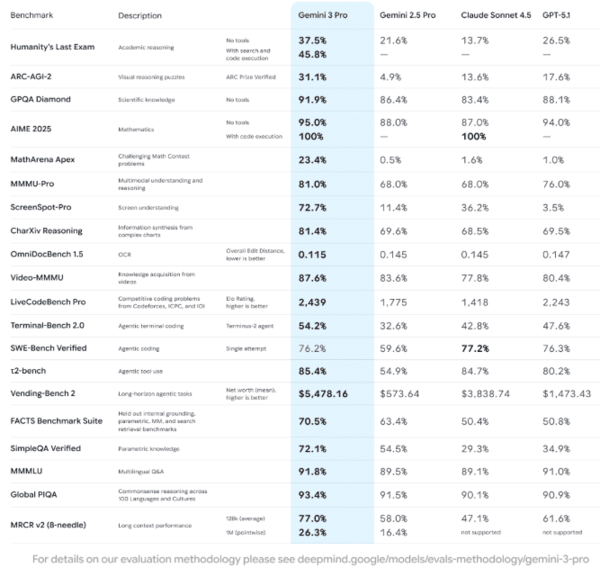
제미나이3, 숫자로 보면 얼마나 센가
구글이 이번에 제미나이3를 내놓으면서 가장 강조한 것은 “추론력(Reasoning)”입니다. 대표적인 지표가 바로 Humanity’s Last Exam이라는 벤치마크입니다.
AI가 사람 수준의 종합 사고력을 얼마나 흉내 내는지를 평가하는 테스트인데, 여기서 Gemini 3 Pro는 37.5%를 기록해, GPT-5.1 26.5%, Claude Sonnet 4.5 (Thinking) 13.7%을 크게 앞섰습니다.
여기에 ▲ARC-AGI-2 같은 추상적 퍼즐 벤치마크 ▲ScreenSpot-Pro 같은 UI·화면 이해 ▲Video-MMMU 같은 영상 기반 이해 ▲Terminal-Bench 2.0, SWE-Bench 같은 에이전트·코딩 벤치마크에서도 제미나이3가 GPT-5.1과 어깨를 나란히 하거나, 앞섰습니다.
물론, 벤치마크 점수는 어디까지나 체감이 아니라 특정 환경에서 “시험 잘 보는 실력”입니다.
하지만 중요한 건, 구글이 처음으로 “우리는 GPT보다 뒤지지 않는다”고 공개적으로 숫자를 깔 만큼, 자신감 보였다는 점입니다.

검색을 갈아엎다, ‘링크의 바다’에서 ‘요약된 세계’로
이번 런칭에서 가장 공격적인 포인트는 따로 있습니다. 바로 제미나이3을 출시 첫날부터 검색에 붙여버렸다는 것이죠.
미국 기준으로, 이제 구글 검색창에서 키워드를 입력하고 ‘AI 모드’를 누르면, 수십 개 링크 대신, 분석형 요약 답변이 먼저 뜨고, 지도·이미지·차트·시뮬레이션 결과까지 한 화면에서 보여주며, 여행 일정·요리 레시피·학습 플랜처럼 복합 작업을 한 번에 수행합니다.
예전의 검색이 “어디 가서 찾아보세요”였다면, 지금의 AI 모드는 “제가 다 찾아보고 요약해서 플랜까지 짜 드릴게요”에 가깝습니다.
와이어드(WIRED)는 이 변화를 두고, 제미나이3이 검색 수익을 오히려 키울 수 있는 무기가 될 거라 분석했습니다. 링크 광고 대신 AI 추천이 클릭률 및 결제 가능성을 더 높이기 때문에 광고 수익을 극대화 할 수 있다는 거죠.
구글 입장에선 한때 두려워하던 “AI가 검색 광고를 잠식할 것”이라는 위협을, 이제는 “AI로 검색 광고를 다시 키우겠다”로 뒤집는 실험에 들어간 셈이죠.
안티그래비티(Antigravity)와 ‘행동하는 IDE’
두 번째로 흥미로운 변화는 코딩 에이전트입니다.
이번에 함께 공개된 ‘안티그래비티(Antigravity)’는 말 그대로 “AI를 중심에 놓고 설계한 개발 환경(IDE)”입니다.
프롬프트 창, 터미널, 브라우저가 한 화면에 붙어 있고 제미나이3가 코드를 쓰고, 실행하고, 결과를 보고, 다음 수정을 제안하는 “왕복 루프”를 IDE 안에서 자동으로 돌려 줍니다.
단순히 “코드를 짜줘” 수준이 아니라, “이 오픈소스 프로젝트를 분석해서, API 서버 구조 바꾸고, 테스트도 고쳐줘” 같은 복잡한 작업을 맡기는 것이 가능하다는 겁니다.
딥마인드의 공식 벤치마크를 보면, 제미나이3 프로는 SWE-Bench Verified에서 59.6%→76.2%, Terminal-Bench 2.0에서 32.6%→54.2%로 이전 세대(제미나이 2.5 프로) 대비 크게 상승했고, GPT-5.1과 비교하면 SWE-Bench에서는 사실상 동급(76.3% 대 76.2%)이거나, Terminal-Bench 2.0에서는 더 높은 성능을 기록했습니다.

GPT-5.1 vs 제미나이3...‘따뜻한 GPT’와 ‘냉정한 제미나이’의 싸움
제미나이3이 나오기 일주일 전, 오픈AI는 GPT-5.1을 공개했습니다.
이번 GPT-5.1는 상당히 인간적입니다. “더 따뜻하고, 더 똑똑하게” 사용자의 선호 톤을 더 잘 맞추고 여러 “성격(personality)”을 제공해, 말투와 대화 스타일을 세밀하게 조정했습니다.
즉, 오픈AI는 “사람 같은 AI”, 구글은 “똑똑한 문제 해결사 AI”라는 색을 더 강화했습니다.
여기에 개발자 관점의 평가를 보면, GPT-5는 코딩·플래닝 능력은 좋지만 품질 편차와 장황한 문제가 발견되고 있고, 제미나이3는 추론과 에이전트 벤치마크는 뛰어나지만, 실제 워크플로우에서의 안정성에 여전히 의문이 있어 여러 실험이 이루어지고 있는 상태입니다.
"이제 벤치마크 대신, 실사용 스토리를 쌓을 때”
서울에서 열린 GAIF 2025(글로벌 AI 포럼)에서 국내 AI 업계와 정부 관계자들은 이미 이런 고민을 공유했습니다.
“지금처럼 글로벌을 따라가는 추격형 전략으로는 주도권 확보가 어렵다”
“데이터센터·GPU 같은 인프라 구축에서 이제는 생태계·적용 사례로 무게 추를 옮겨야 한다”
“연구비를 받기 위한 행정보다, 실제 성공 사례를 만드는 게 중요하다”
제미나이3가 보여주는 건, 모델 그 자체의 스펙 경쟁을 넘어, 검색, 개발도구, 로봇, 업무자동화 에이전트까지 ‘생활 곳곳에 AI를 심는 전략’입니다.
한국이 여기서 배울 포인트는 두 가지입니다.
▲우리도 파운데이션 모델을 만들어야 한다는 강박에 갇히지 말 것
모든 레이어를 다 따라잡겠다는 건 현실적으로 버거운 전략입니다. 대신 한국이 이미 강점을 가진 게임·엔터·제조·교육·금융 같은 실전 영역에서 AI 에이전트를 가장 먼저, 가장 잘 적용하는 나라가 되는 쪽이 훨씬 현실적입니다.
▲한국어·한국 서비스 컨텍스트를 품은 ‘현장형 에이전트’에 집중할 것
구글·오픈AI가 한국어를 지원해도, 한국식 행정·규제·교육·업무관행까지 깊이 이해하는 에이전트는 여전히 로컬 플레이어의 영역입니다.
“GPU 몇 만 장”이 아니라, “어떤 일을 AI에게 먼저 맡기고, 한국 사람이 그 위에서 어떤 가치를 만들게 할 것인가”가 전략의 중심이 되어야 합니다.
점수의 시대에서, ‘일 잘하는 AI’의 시대로
제미나이3는 분명 하나의 분기점입니다.
HLE 37.5, 각종 벤치마크 최상위 점수, 검색과의 통합, 안티그래비티, 에이전트 벤치마크의 상향. 이 숫자와 제품 조합은, 구글이 다시 한 번 “우리가 이 판의 원조다”라고 주장할 근거를 만들어 줍니다.
하지만 10년 동안 테크 칼럼을 쓰며 한 가지 배운 게 있다면, “테크 세계에서 스펙 시트는 시작일 뿐”이라는 겁니다.
이제 경쟁의 초점은 바뀌고 있습니다.
“누가 벤치마크에서 더 높은 점수를 찍었는가”에서 “누가 더 많은 사람의, 더 많은 일을 실제로 대신해 주는가”로 말입니다.
제미나이3는 그 전환의 초입에 서 있는 모델입니다. 머리는 이미 상당히 좋아졌고, 손발은 이제 막 일을 배우기 시작한 상태죠.
사용자 입장에서는 “이 AI가 나 대신 무엇을 해줄 수 있지? 그리고 그게 지금의 내 일, 내 비즈니스, 내 업무 방식을 얼마나 바꾸게 될까?”를 확인할 때입니다.
앞으로 몇 달, 제미나이3과 GPT-5.1, 그리고 각 빅테크의 에이전트들이 이 질문에 어떻게 답하는지가, 진짜 승자를 가를 겁니다.
테크풍운아 칼럼니스트 scienceazac@naver.com
![[동학] 카카오톡 친구탭, 결국 12월 롤백… “격자형 피드는 선택 옵션으로”](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5517_10550_1119_1763853080_120.jpg)


![[테크 칼럼] 제미나이3, GPT-5.1을 넘다…AI는 이제 ‘일을 대신하는 시대’로 간다](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5457_10454_4847_1763621329_120.jpg)


![[낭만 테크 시대] AI 대항해 시대](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5603_10714_4334_1764121414_160.jpg)


