생성형 AI 실무 성능 검증 위한 자체 벤치마크 개발…허깅페이스 리더보드도 동시 공개
삼성전자가 인공지능(AI) 모델의 실질적 업무 효율을 정량화할 수 있는 독자적 성과지표 ‘트루벤치(TRUEBench)’를 9월 25일 전격 공개했다. 이 지표는 실제 사내 업무 적용 경험을 기반으로 설계됐으며, 글로벌 오픈소스 플랫폼 허깅페이스(Hugging Face)에도 리더보드 형식으로 공개되며 개방형 생태계와의 협력도 강화했다.
AI ‘실무 성능’ 측정 시대…삼성의 선택은 ‘트루벤치’
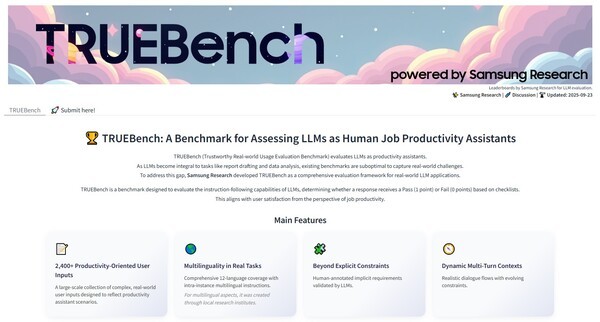
트루벤치는 삼성전자 DX(디바이스경험)부문 산하 선행 연구조직인 삼성리서치가 개발했다. 기존의 언어모델 벤치마크가 주로 창의성, 추론, 언어 이해 능력 중심이었다면, 트루벤치는 업무 생산성과 효율성 중심의 실용형 지표라는 점에서 차별화된다.
총 10개 카테고리, 46개 업무유형, 2,485개 평가 기준으로 구성돼 있으며, 사용자의 간단한 명령부터 최대 2만 자 분량의 문서 요약까지 다양한 시나리오를 커버한다. 이를 통해 기업 내부에서 생성형 AI를 활용할 때 실제 어떤 업무에서 성과를 내고 있는지를 구체적으로 측정할 수 있다.
최대 5개 모델 동시 비교…성과와 효율성 함께 본다
트루벤치는 단일 모델 평가를 넘어서, 최대 5개 AI 모델을 동시에 비교할 수 있는 구조를 제공한다. 결과 응답의 평균 길이, 처리 시간, 정답률 등 다양한 수치를 기반으로 정확성과 효율성의 균형을 검토할 수 있게 설계됐다.
사용자는 사내 또는 상용 LLM 중 원하는 모델을 선택하여 다중 비교 실험을 진행할 수 있으며, 이는 엔터프라이즈 AI 활용 전략 수립에 실질적인 인사이트를 제공한다.
12개 언어 지원…‘교차 언어 번역 평가’까지 가능
삼성의 트루벤치는 영어·한국어·일본어·중국어·스페인어 등 총 12개 언어를 지원하며, 특히 다국어 혼합 환경에서의 문장 이해와 번역 정확도까지 평가할 수 있도록 설계됐다.
영어 중심의 기존 벤치마크의 한계를 넘어, 복잡한 글로벌 업무 환경에서의 AI 적합성 검증까지 염두에 둔 것이다. 이는 삼성전자의 AI가 단순히 기술 데모 수준을 넘어, 글로벌 고객과 파트너 환경에 대응 가능한 ‘실전형 AI’로 진화하고 있다는 방증이기도 하다.
사람과 AI의 협업 평가체계…신뢰도 높인 구조
트루벤치는 평가 기준의 공정성과 객관성을 높이기 위해, ‘사람이 설계하고 AI가 교차 검증하는’ 평가 구조를 도입했다. 사람이 직접 설정한 기준을 AI가 재검토함으로써 오류·모순·불필요한 제약을 줄이고, 반복 교차 검증을 통해 평가 결과의 일관성과 신뢰성을 확보했다.
이는 최근 생성형 AI의 평가에서 문제가 되는 주관적 편향을 줄이는 데 핵심적인 역할을 하며, 엔터프라이즈 고객의 신뢰를 높이기 위한 기술적 기반으로 작용한다.
허깅페이스 리더보드 공개…글로벌 오픈 생태계 합류
삼성전자는 트루벤치의 데이터 샘플과 평가 결과를 글로벌 오픈소스 플랫폼 ‘허깅페이스’에 동시 공개했다. 이로써 외부 연구자·개발자들도 해당 벤치마크를 자유롭게 활용하고, 다양한 모델의 성능을 리더보드 형식으로 비교할 수 있게 됐다.
이러한 공개 전략은 삼성이 AI 분야에서도 개방형 기술 리더십을 강화하고, 글로벌 AI 생태계와의 시너지를 도모하려는 전략적 행보로 해석된다.
신주백 기자 jbshin@kmjournal.net
![[동학] 카카오톡 친구탭, 결국 12월 롤백… “격자형 피드는 선택 옵션으로”](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5517_10550_1119_1763853080_120.jpg)


![[테크 칼럼] 제미나이3, GPT-5.1을 넘다…AI는 이제 ‘일을 대신하는 시대’로 간다](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5457_10454_4847_1763621329_120.jpg)





