중국 스타트업 문샷AI가 내놓은 오픈소스 모델 ‘키미-K2-싱킹(Kimi-K2-Thinking)’이 글로벌 개발자 커뮤니티에서 빠르게 존재감을 넓히고 있다.
출시 직후부터 “딥시크의 재림”이라는 반응이 쏟아지는 가운데, 훈련 비용이 딥시크보다 낮다는 소식까지 전해지며 관심이 집중되고 있다.
“딥시크보다 14억 원 저렴”… 엔비디아 구형 GPU로 학습
미국 경제매체 CNBC에 따르면, 문샷AI의 이번 모델 학습 비용은 약 460만 달러(67억 원)로, 딥시크-V3의 557만 달러(82억 원)보다 낮은 수준이다.
문샷 측은 정확한 비용을 밝히지 않았지만, 10일(현지시간) 진행된 레딧(Reddit) AMA(Ask Me Anything) 행사에서 한 관계자가 “미국 기업보다 훨씬 저렴한 비용으로 훈련했다”고 언급했다.
그는 구형 엔비디아 ‘H800’ GPU를 활용해 모델을 학습했다고 밝히며, “미국의 GPU 제재 이전 확보한 장비로도 충분히 경쟁 가능한 성능을 낼 수 있었다”고 덧붙였다.
이 발언의 계정명은 문샷 공동 창립자 우유신(Yuxin Wu)이 자주 사용하는 아이디 ‘ppwwyyww’로 확인되며, 내부 정보로 해석되고 있다.
‘문케이크’와 ‘리니어 어텐션’… 연산 효율 5배 높인 비결
문샷AI는 비용 절감의 핵심으로 ‘문케이크(Mooncake)’ 알고리즘과 ‘Kimi Linear Attention’ 아키텍처를 제시했다.
문케이크는 기존 학습 방식보다 최대 5배 높은 효율을 구현했으며, 리니어 어텐션은 디코딩 속도를 높이면서 메모리 사용량을 대폭 줄였다.
결과적으로 문샷은 고성능 GPU 없이도 GPT-5급 모델에 근접한 결과를 달성했다고 주장했다.
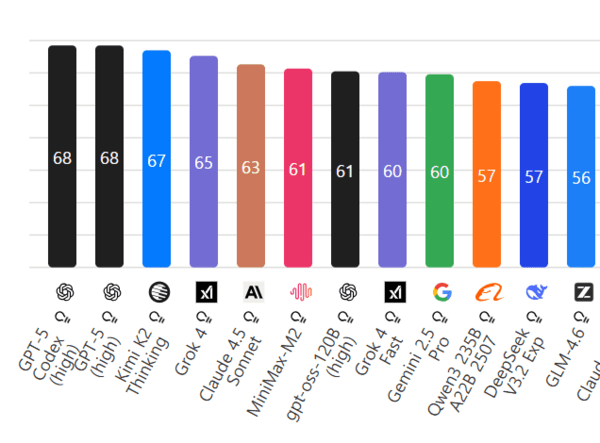
벤치마크서 GPT-5 추격… “오픈소스계의 왕좌 노린다”
AI 벤치마크 전문기관 Artificial Analysis의 ‘지능 점수(Intelligence Score)’에 따르면, GPT-5와 GPT-5 Codex는 68점, Kimi-K2-Thinking은 67점을 기록하며 GPT-5를 1점 차로 추격했다.
이는 Grok-4(65점), Claude 4.5 Sonnet(63점) 등 기존 상위권 모델을 모두 넘어선 수치다.
특히 ‘BrowseComp(웹 검색)’과 ‘SEAL-0(현실 정보 수집)’ 항목에서는 GPT-5를 능가하며, 실사용 능력에서도 경쟁력을 입증했다.
“인간 개입 없이 300단계 도구 호출”… 자율 에이전트 완성
문샷AI는 이번 모델에서 에이전트(AI Agent) 기능을 대폭 강화했다.
키미-K2는 200~300단계의 연속적 툴 호출(tool use)을 자체 수행해, 검색·코드 실행·계획 수립 등을 인간 개입 없이 처리할 수 있다.
이는 LLM의 한계를 넘어 자율적 문제 해결이 가능한 ‘Thinking Agent’ 시대를 예고한다는 평가를 받고 있다.
“K3는 언제 나오나”… 커뮤니티서 폭발적 반응
출시 이후 ‘키미-K2-싱킹’은 허깅페이스(Hugging Face)에서 8만 회 이상 다운로드되며 오픈소스 모델 부문 1위를 차지했다.
X(트위터) 게시물은 조회수 460만 회를 돌파했고, 글로벌 개발자 커뮤니티에서는 “K3는 언제 출시되나”라는 기대감이 쏟아졌다.
이에 대해 문샷 관계자는 “알트먼의 1조 달러짜리 데이터센터가 완공되기 전까지는요”라며 여유 있는 답변을 내놓았다.
중국 AI의 반격… “K2, 오픈소스 생태계의 새로운 주자”
문샷AI는 올해 7월 첫 모델 ‘키미-K2’를 공개하며 오픈소스 시장에 진입했지만, 당시에는 GPT-4, Grok-4 등 신작에 밀려 큰 반향을 얻지 못했다.
그러나 이번 ‘K2-싱킹’은 효율·성능·실용성 세 요소를 모두 갖춘 모델로 평가받으며, 다시금 글로벌 AI 시장의 주목을 받고 있다.
테크 업계에서는 이번 모델을 두고 “중국 AI의 기술 독립 선언이자, 오픈소스 생태계의 반격 신호탄”이라는 해석을 내놓고 있다.
신주백 기자 jbshin@kmjournal.net
![[동학] 카카오톡 친구탭, 결국 12월 롤백… “격자형 피드는 선택 옵션으로”](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5517_10550_1119_1763853080_120.jpg)


![[테크 칼럼] 제미나이3, GPT-5.1을 넘다…AI는 이제 ‘일을 대신하는 시대’로 간다](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5457_10454_4847_1763621329_120.jpg)



![[낭만 테크 시대] AI 대항해 시대](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5603_10714_4334_1764121414_160.jpg)

