'전문가 혼합' 모델 단점 개선한 '그룹화 전문가 혼합' 모델 소개

중국 빅테크 기업 화웨이가 자사 칩을 활용한 인공지능(AI) 훈련 기술을 개발했으며 이는 딥시크의 훈련법보다 효율적이라고 주장했다.
홍콩 사우스차이나모닝포스트(SCMP)와 연합뉴스에 따르면 화웨이의 이런 AI 모델 설계 기술의 발전을 소개하면서 중국이 미국 기술에 대한 의존을 줄이려는 노력의 하나로 중요한 의미를 갖는다고 5일 보도했다.
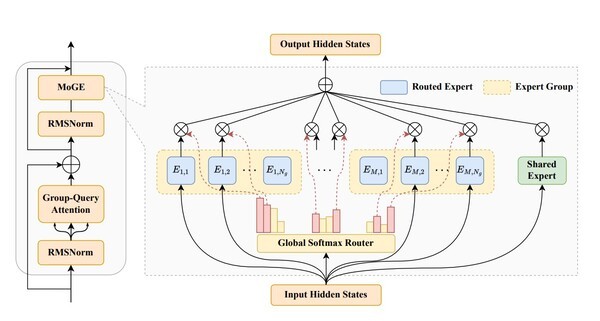
화웨이의 대형언어모델(LLM) 개발팀인 판구(Pangu)팀은 지난달 28일 논문저장 사이트 'arXiv'에 공개한 '판구 프로 MoE'란 논문에서 딥시크가 '저비용 고효율' AI 모델 개발에 활용한 '전문가 혼합'(MoE·Mixture of Experts) 모델을 개선한 '그룹화 전문가 혼합'(MoGE·Mixture of Grouped Experts) 모델을 소개했다.
MoE란 문제 해결에 필요한 최적의 전문가들만 선별해 활용하는 개념을 LLM 학습 방법에 적용한 것으로 딥시크가 엔비디아의 저사양 칩을 적게 쓰면서도 효율적인 AI 모델을 개발하는 데 중요한 역할을 했다.
그러나 화웨이 판구팀은 MoE는 각 입력 토큰에 대해 활성화되는 매개변수(파라미터)의 비율이 매우 낮아 일반적 LLM보다 효율성은 뛰어나지만, 일부 전문가들이 다른 전문가들보다 훨씬 자주 활성화되는 현상이 종종 나타남에 따라 시스템 비효율성의 원인이 될 수 있다고 지적했다.
이에 따라 판구팀은 논문에서 MoE보다 전문가 작업 부하의 균형을 잘 잡고 선택하는 그룹화된 전문가들의 혼합 아키텍처인 MoGE를 소개한다고 밝혔다.
논문에 따르면 MoGE는 사전에 정의된 각 전문가그룹 안에서 동일한 수의 전문가들을 활성화하도록 토큰을 제약한다. MoGE가 사용한 그룹 균형 분배 전략은 전문가를 고유하고 겹치지 않는 그룹으로 분할하며 각 그룹을 특정 컴퓨팅 장치에 할당하는 방식이다.
이에 따라 AI 모델 훈련이 다중 장치에 분산될 때 장치 간 계산 부하를 균형 있게 배분해 처리량을 대폭 향상할 수 있다. 특히 추론 단계에서 이런 효과가 두드러진다.
아울러 화웨이는 자사의 신경망처리장치(NPU) 어센드를 활용한 MoGE 기반 희소 모델인 '판구 프로(Pro) MoE'를 구축했다고 밝혔다. 이 모델은 매개변수 총 720억개 가운데 토큰당 160억개가 활성화된다.
판구 프로 MoE의 구성은 광범위한 시스템 시뮬레이션 연구를 통해 어센드 300I 듀오 및 어센드 800I A2에 최적화됐다.
판구팀의 실험 결과 MoGE는 어센드 NPU에서 모델 훈련과 추론에서 전문가 계산부하 균형 조정과 실행 효율성을 향상해 추론 성능은 카드당 초당 1천148토큰을 달성했다.
판구팀은 어센드 NPU가 대규모 병렬화를 통해 판구 프로 MoE를 훈련해 1천억 파라미터(100B) 미만급에서 선도적 모델이 될 수 있다며 벤치마크 평가 결과 즈푸의 GLM-Z1-32B나 알리바바의 Qwen3-32B 등을 앞섰다고 밝혔다.
앞서 화웨이는 지난달 7일에는 어센드 NPU에 최적화한 LLM인 '판구 울트라 MoE'를 공개하는 등 미국 엔비디아의 칩에 의존하지 않고 첨단 AI 모델을 개발할 수 있다는 점을 보여줬다.
신주백 기자 jbshin@kmjournal.net
- 中 빅테크, 엔비디아 없이 AI 개발 준비...중국산으로 대체
- 화웨이 AI칩 쓰면 전 세계 어디든 제재…미국, 글로벌 기술 통제 선언
- 중국 딥시크, ‘R1’ 추론 AI 모델 업그레이드…코딩 능력, 오픈AI 턱밑까지 추격
- 딥시크부터 샤오미까지… 中 AI, 챗GPT에 도전장
- [분석리즘] “엔비디아 독점 깨다” 퓨리오사AI, 국산 칩으로 AI 주권을 설계하다
- "사우디 아람코도 딥시크 깔았다"…중국 AI 확산
- 전세계 '톱100 AI 과학자' 절반이 중국인…美서 인재 유치 경쟁
- 딥시크를 잇는 ‘중국발 AI 쇼크’…문샷AI ‘키미 K2’
- 엔비디아 OUT? 중국, AI 반도체 독립 가속화…‘딥시크 모멘트’는 시작일 뿐
- "알리바바, AI 반도체 독립 선언…中 테크굴기 가속한다"
- 화웨이, 자체 HBM 전격 공개…SK하이닉스·삼성전자에 'AI 메모리 도전장'
- 화웨이, LLM 경량화 기술 ‘SINQ’ 전격 공개
- 화웨이, 미국 제재 속에서도 AI 자립 가속…‘어센드 칩’으로 독자 생태계 굳힌다
![[동학] 카카오톡 친구탭, 결국 12월 롤백… “격자형 피드는 선택 옵션으로”](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5517_10550_1119_1763853080_120.jpg)


![[테크 칼럼] 제미나이3, GPT-5.1을 넘다…AI는 이제 ‘일을 대신하는 시대’로 간다](https://cdn.kmjournal.net/news/thumbnail/custom/20251126/5457_10454_4847_1763621329_120.jpg)





